The Identity Problem
Disclaimer: views expressed are my own and are not endorsed by my employer.
It’s a famous joke that naming things is one of the hardest problems in computer science. I think this alludes to a fundamental truth behind so many of the problems I encounter every day as a software engineer. Let me ruin the joke and reword it a bit.
The hardest problem in computer science is deciding whether two things are the same thing, or different. I don’t know if there’s already a name for this concept, but I’ll just call it the “identity problem”.
The most basic solution to the identity problem is binary:
- 0 is equal to 0.
- 1 is equal to 1.
- 1 is not equal to 0.
But this solution is not immediately useful; I need to build more identities on top of this in order to do anything fun. That’s where names come in.
After all, the purpose of naming something is to distinguish it from other things. When we need to name something at StrongDM we sometimes play a game called “bracketology”, in which we brainstorm names and then vote to eliminate them in a March Madness-style bracket tournament, leaving one name victorious. Sometimes the names are pretty similar and we decide based on aesthetic and human factors like “that name is too long and I don’t want to type it.” But sometimes we have to decide between names that mean very different things.
Naming things in software is like trying to partition a 1,000-dimensional space. If I name a thing “Foo”, I categorize it in one partition. “Bar” will place it another partition. Maybe I haven’t even encountered any other data points in either of these partitions yet. Some engineer in the future will get assigned to build a “Bar”-ish looking feature, find my “Bar” in the codebase, and realize they should probably tack their thing onto my thing. On the other hand if I name it “Foo”, hopefully they’ll realize that my thing is not really meant for “Bar” purposes, even though it might look like it. The name itself doesn’t matter much, but it does matter that it helps myself and other engineers distinguish one thing from another.
Identity mismatches
I think a majority of technical debt is caused by identity mismatches. I define an identity mismatch as one thing that should be several different things, or different things that should be one.
For example, once upon a time StrongDM only worked with Postgres datasources.
We kept the password for each Postgres datasource in an encrypted field called… password.
When we added support for SSH, the password field was the perfect place to put the private key.
Years later, we support all manner of things that look nothing like a Postgres server, and the password field is now unrecognizable.
We could try and pick a more suitable name for this field like EncryptedData, but it won’t fix the fact that the code insists it is one thing when it is really many different things.
Probably the clearest and most common warning sign of a growing one-to-many identity mismatch is when I have a function like this:
func DoThing() {
}
And I feel the urge to add a boolean flag like this:
func DoThing(doOtherThing bool) {
}
Honestly, this is not a big deal. But I take it as a sign that somewhere in the stack, one thing is actually turning out to be two different things.
The other case is even more common: many different things that should be one. This often looks like a snippet of code copy-pasted and slightly edited fifty times. I usually have the urge to DRY up those fifty snippets into a single function. But is that really wise?
Once again, names can help me determine the best solution to this identity problem.
If I can replace those fifty snippets with one function that has a clear, specific name like CheckPermissions (and the same is true for its parameters), that probably means it really is one single thing that deserves its own place.
But if the best I can come up with is something vague like Initialize, or a composite name like PrepareFoosAndAddBars, maybe it’s two or more things, or the mismatch lies somewhere deeper.
Partitions in 1,000-dimensional space
There are many different ways to partition a 1,000-dimensional space. Each is a valid solution to the identity problem, and each has its own pros and cons. For example, if I’m using microservices to build a social media site, I could partition my system like this:
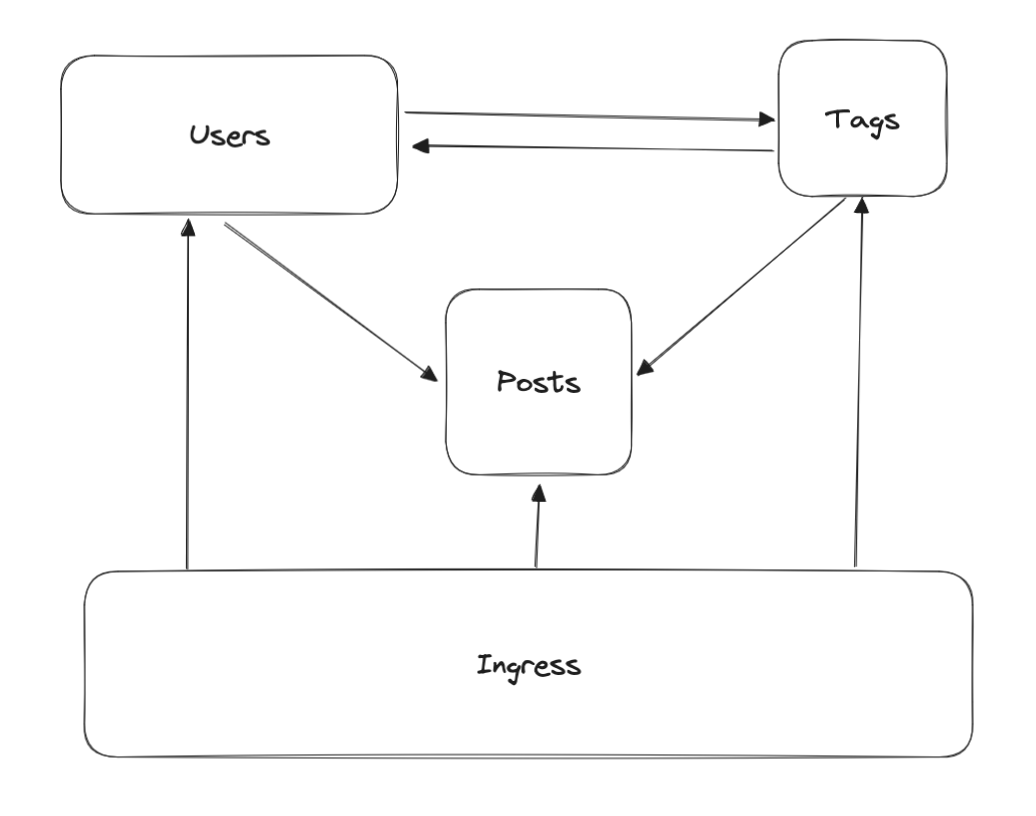
The advantage of this partitioning is that it’s easy to understand; each type of thing has its own service to keep track of it. The downside is, each service is kind of useless on its own. They’re deeply intertwined.
Here’s another partitioning that happens almost inevitably and automatically, and from which you stray at your own peril (also known as Conway’s law):
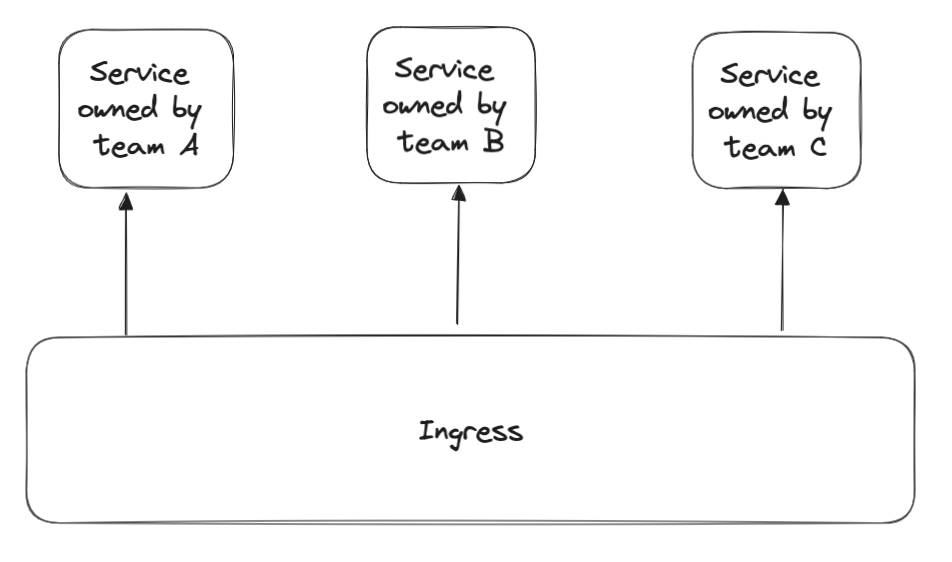
This last example demonstrates that the identity problem involves human factors, which are messy and unpredictable. To find the best solution, I need a perfect understanding of my customers and my business, and perfect knowledge of the future. In lieu of clairvoyance, the best I can do is to gather as much information as possible and prioritize frequent refactors to eliminate the identity mismatches that inevitably crop up. This is one of the things that makes writing software so challenging and fun!
Playing God
In Genesis, God creates the world by separating things from each other and naming them:
And God said, “Let there be light,” and there was light. God saw that the light was good, and he separated the light from the darkness. God called the light “day,” and the darkness he called “night.”
Maybe that’s why writing software feels to me like playing God, and why it’s easy for me to end up on a power trip when coding.
It’s interesting that afterward he lets Adam name every animal:
Now the Lord God had formed out of the ground all the wild animals and all the birds in the sky. He brought them to the man to see what he would name them; and whatever the man called each living creature, that was its name.
It’s wild to think of a creator who shares his power of creation with one of the things he created. What an awesome, terrifying privilege.