The Poor Man's Threading Architecture
The game industry hit Peak Advice Blog a while ago. Every day I read
skim ten articles telling me how to live.
Fear not! I would never give you useful advice. This series is about me writing bad code and you laughing at my pain.
First Contact
Say you have some voxels which occasionally get modified. You regenerate their geometry like so:
voxel.Regenerate();Because you are a masochist, you want to do this on a separate thread.
Rather than redesign your engine, you simply spawn a worker thread and give it a list of voxels to process. Easy in C#:
Queue<Voxel> workQueue;
static void worker()
{
while (true)
{
Voxel v = workQueue.Dequeue();
lock (v)
{
v.Regenerate();
}
}
}
new Thread(new ThreadStart(worker)).Start();
// And awaaaaaaay we go!
workQueue.Enqueue(voxel);The lock signals to other threads "hey, I'm using this". If the other threads also acquire locks before using the object, then only one thread will access it at a time.
Kaboom! It crashes when thread A dequeues an item at the exact moment when thread B is enqueueing one. You need a lock on the queue as well.
This is Hard and Boring and Slow
Turns out, without a lock you can't trust even a single boolean variable to act sane between threads. (Not entirely true. For wizards, there are atomic operations and something about fences. Out of scope here!)
Sprinkling locks everywhere is tedious, error-prone, and terrible for performance. Sadly, you need to rethink your engine from the ground up with threads in mind.
The Right Way
Why am I even including this? Ugh.
You read a few articles on modern AAA engines, where you find a diagram like this:
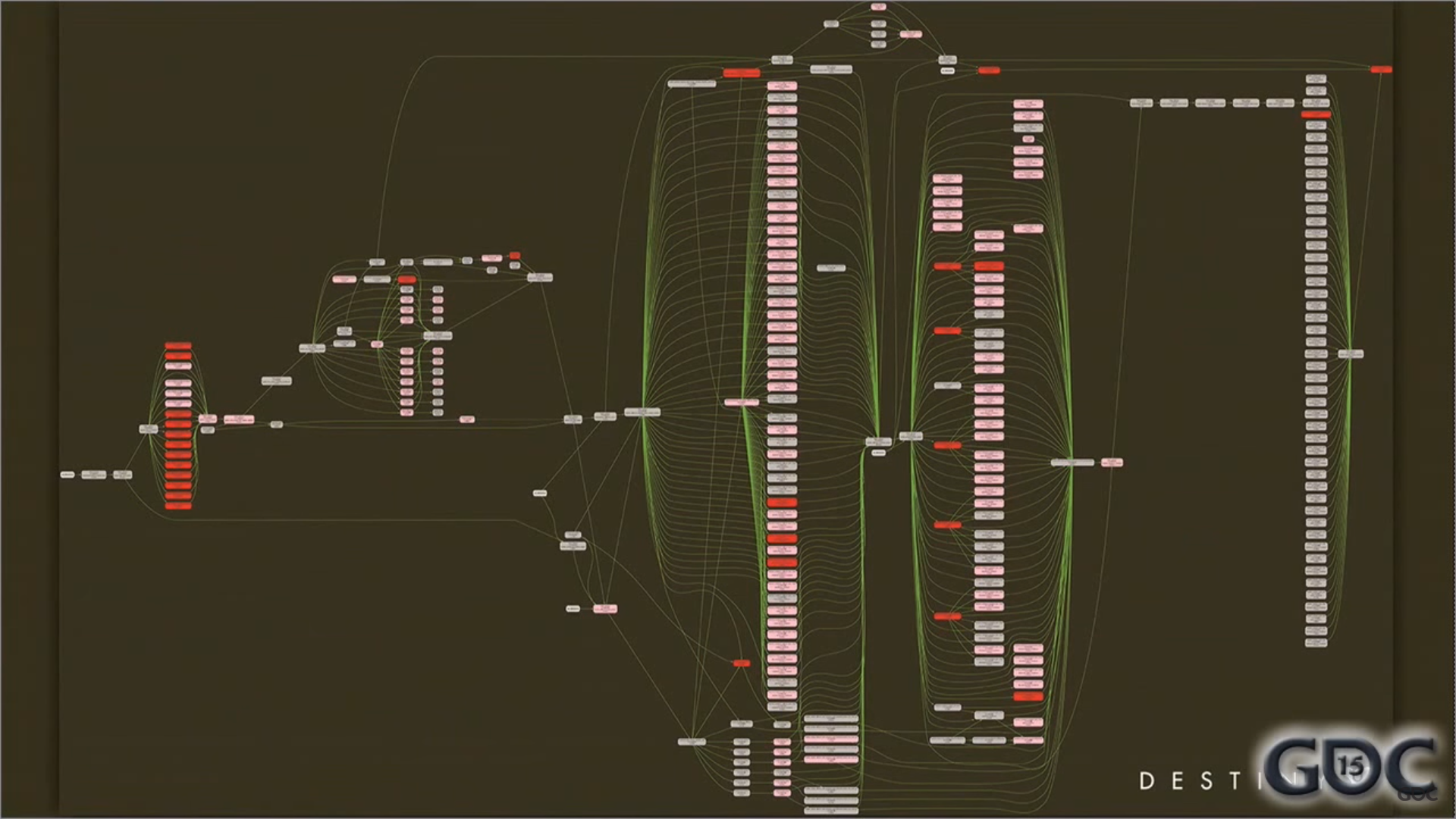
This is the job graph from Destiny. AAA engines split their workload into "jobs" or "fibers". Some jobs depend on others. The graph has bottlenecks that split the work into phases. Within phase 1, tons of jobs execute in parallel, but all of them must finish before phase 2 starts.
With jobs, you wouldn't have to lock individual pieces of data. The dependency graph ensures that jobs run in the right order, and that nothing runs in parallel unless you're okay with it. You also don't have to think about individual threads — a scheduler delegates jobs to a pool of threads.
Here's another diagram you stumble across:
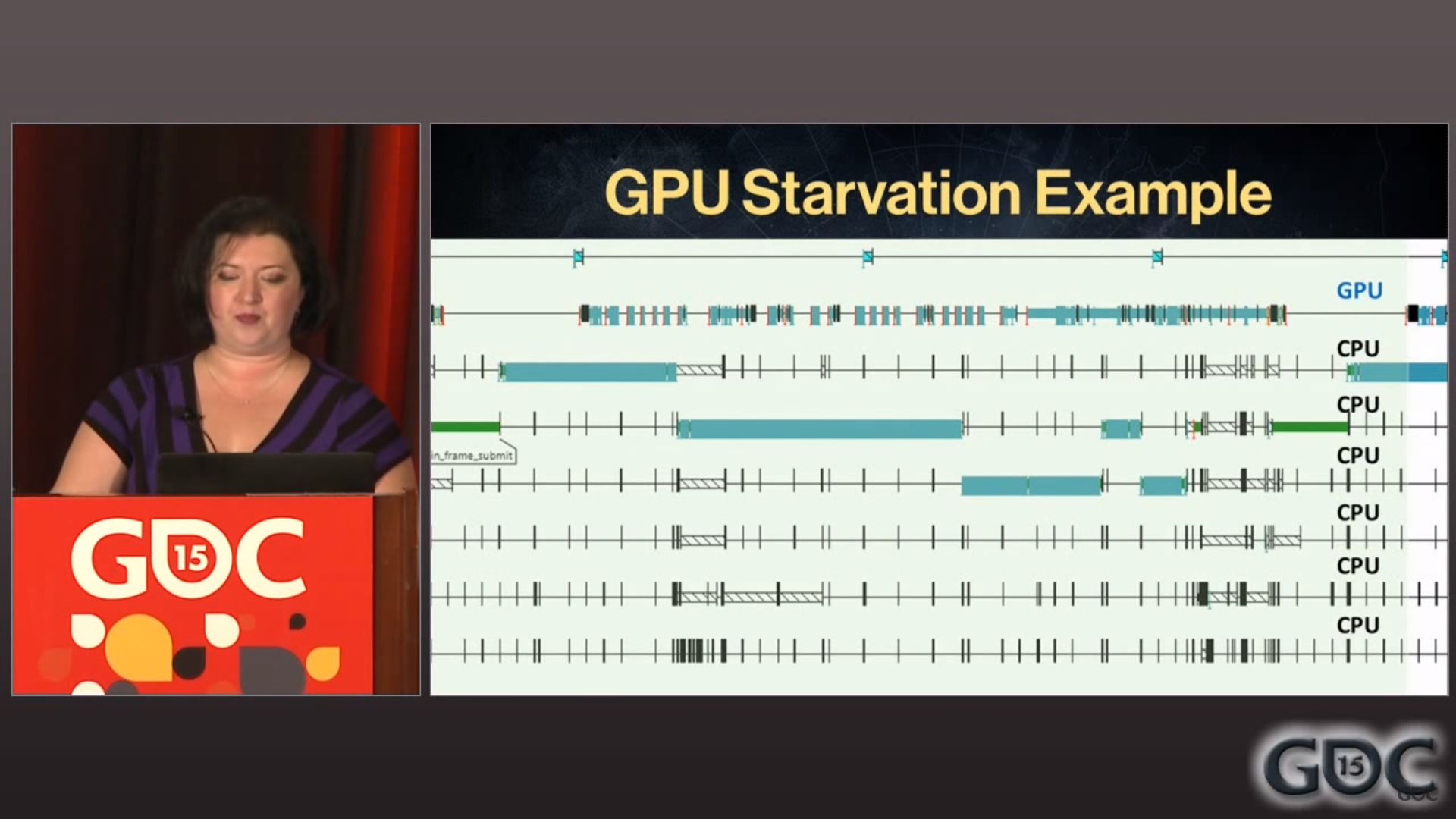
This shows the workload of the GPU and each CPU over time as the game renders a single frame. The goal is to fill all those holes so you use every bit of available compute power at maximum efficiency.
The Quick and Dirty Way
In a brief flash of clarity, you realize that you are not Bungie. You check your bank account, which sadly reports a number slightly lower than $500 million.
You recall the Pareto Principle, also known as the "80/20 rule". You decide to write 80% of a decent architecture for only 20% of the work.
You start with a typical game loop:
while (true)
{
// Process window and input events
SDL_PumpEvents();
SDL_Event sdl_event;
while (SDL_PollEvent(&sdl_event))
{
// ...
}
physics_step();
game_logic();
render();
// Present!
SDL_GL_SwapWindow(window);
}Side note: a while back you also switched to C++. Masochism level up.
What can you move off the main thread? If you touch OpenGL or anything within a mile of the windowing system from another thread, the universe explodes. For now, you keep graphics and input (SDL_PollEvent) on the main thread.
That leaves physics and game logic. You give each its own thread. Since you need to spawn/modify/query physics entities in game logic, no other physics can happen while you're in a game logic update. The rest of the time, the physics thread can work in the background.
Sounds like a perfect case for a lock:
std::mutex physics_mutex;
void physics_loop()
{
while (true)
{
std::lock_guard<std::mutex> lock(physics_mutex);
physics_step();
}
}
void game_logic_loop()
{
while (true)
{
{
std::lock_guard<std::mutex> lock(physics_mutex);
game_logic();
}
render();
}
}In this setup, your render() function can't read or write any physics data for fear of explosions. No problem! In fact, that limitation might be considered a feature. However, the render() function also can't make any OpenGL calls since it's not on the main thread.
You re-watch the Destiny GDC presentation and notice a lot of talk about "data extraction". In a nutshell, Destiny executes game logic, then extracts data from the game state and lines it up for a huge fan-out array of render threads to process efficiently.
That's essentially what your render() function will do: go through the game state, generate graphics commands, and queue them up. In your case, you only have one render thread to execute those commands. It might look like this:
enum class RenderOp
{
LoadMesh,
FreeMesh,
LoadTexture,
FreeTexture,
DrawMesh,
Clear,
// etc.
};
BlockingQueue render_queue;
void main_loop()
{
while (true)
{
RenderOp op = render_queue.read<RenderOp>();
switch (op)
{
case LoadMesh:
int count = render_queue.read<int>();
Vec3* vertices = render_queue.read<Vec3>(count);
// etc...
break;
case FreeMesh:
// etc...
}
}
}It's a graphics virtual machine. You could give it a pretentious name like GLVM.
Now in your render() function, you just write commands to the queue:
void render()
{
render_queue.write(RenderOp::Clear);
for (MeshRenderer& mesh : mesh_renderers)
{
render_queue.write(RenderOp::DrawMesh);
render_queue.write(mesh.id);
// etc.
}
render_queue.write(RenderOp::Swap);
}This will work, but it's not the best. You have to lock the queue every time you read from or write to it. That's slow. Also, you need to somehow get input data from the main thread to the game logic thread. It doesn't make sense to have queues going both directions.
Instead, you allocate two copies of everything. Now, the game logic thread can work on one copy, while the main thread works on the other. When both threads are done, they swap.
Now you only have to use a lock once per frame, during the swap. Once the threads are synced, the swap operation is just two pointer reassignments.
Furthermore, you can keep the render command lists allocated between frames, which is great for performance. To clear one, just reset the pointer to the start of the list. Now you don't have to worry about implementing a queue with a ring buffer. It's just an array.
Our Bright and Glorious Future
For wizards, this is all wrong, because graphics drivers do command queueing anyway, and jobs and fibers are the right way. This is like Baby's First Threaded Renderer. But it's simple, it gets you thinking in terms of data flow between threads, and if you eventually end up needing a job system, you're already halfway there.
This setup might also make the switch to Vulkan easier. If you keep all your data extraction in one place and make it read-only, it should be trivial to split into multiple threads, each with their own render queue.
You can see a poorly-commented cross-platform implementation of this idea here. Potentially useful parts include the SDL loop, GLVM, and the swapper.
If you enjoyed this article, try these:
But here's a better idea: watch the Destiny GDC talk.
Thanks for reading!